
Page 703 - Emerging Trends and Innovations in Web-Based Applications and Technologies
P. 703
International Journal of Trend in Scientific Research and Development (IJTSRD) @ www.ijtsrd.com eISSN: 2456-6470
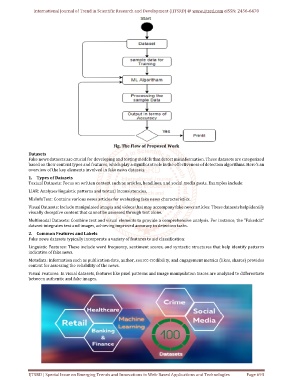
Fig. The Flow of Proposed Work
Datasets
Fake news datasets are crucial for developing and testing models that detect misinformation. These datasets are categorized
based on their content types and features, which play a significant role in the effectiveness of detection algorithms. Here’s an
overview of the key elements involved in fake news datasets.
1. Types of Datasets
Textual Datasets: Focus on written content such as articles, headlines, and social media posts. Examples include:
LIAR: Analyzes linguistic patterns and textual inconsistencies.
MisInfoText: Contains various news articles for evaluating fake news characteristics.
Visual Datasets: Include manipulated images and videos that may accompany fake news articles. These datasets help identify
visually deceptive content that cannot be assessed through text alone.
Multimodal Datasets: Combine text and visual elements to provide a comprehensive analysis. For instance, the “Fakeddit”
dataset integrates text and images, achieving improved accuracy in detection tasks.
2. Common Features and Labels
Fake news datasets typically incorporate a variety of features to aid classification:
Linguistic Features: These include word frequency, sentiment scores, and syntactic structures that help identify patterns
indicative of fake news.
Metadata: Information such as publication date, author, source credibility, and engagement metrics (likes, shares) provides
context for assessing the reliability of the news.
Visual Features: In visual datasets, features like pixel patterns and image manipulation traces are analyzed to differentiate
between authentic and fake images.
IJTSRD | Special Issue on Emerging Trends and Innovations in Web-Based Applications and Technologies Page 693